实现超分辨率重建的算法有很多,包括经典的基于插值的方法,如双立方插值。而基于机器学习的算法SRCNN可以达到比插值更好的效果。
原理阐述
使用卷积神经网络训练模型,将上采样图像转化为高分辨率图像。其中上采样图像使用双立方插值对原图进行放大得到,而转化成的高分辨率图像虽然和上采样图像大小一样,但比三次立方插值放大得到的图像清晰,因此SRCNN成为了比双立方插值效果更好的方法。
假设存在一种模糊图像到高分辨率图像的映射关系,该神经网络的目的就是求解出这个映射关系。因为图像通常使用矩阵表示,不同的图像对应着不同的矩阵,图像的特点可以使用矩阵的特征表示。而图像千变万化,如果使用小矩阵来拆解图像,使用多个小矩阵来表示一个图像的话,那么所有的图像都可以用这些小矩阵来表示了。所以该神经网络只要可以对小矩阵进行处理,将其映射成高分辨率的小矩阵,即可将图像从模糊映射成高清。因为双立方插值放大的图像并不清晰,结合该方法,即可实现得到放大的清晰图片的效果。
网络结构
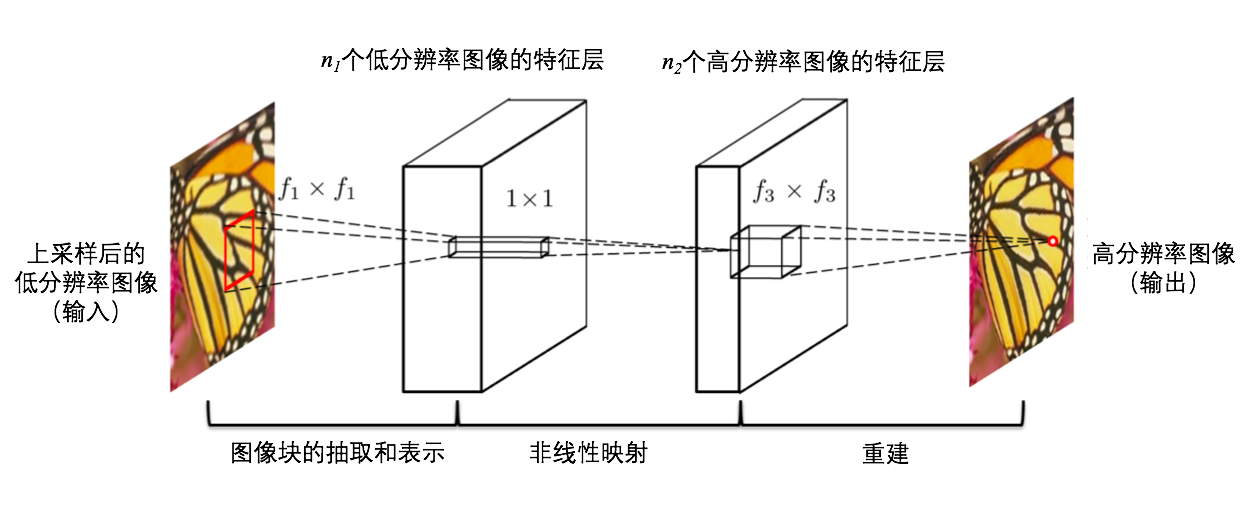
SRCNN网络分为三层,每层的功能如下:
提取和表示图像块:
该卷积层的输入数据为拆分好的图像块的Y通道。
该层负责提取图像块的特征。特征个数为$n_1$,该层卷积核大小为$f_1*f_1$
非线性映射
该卷积层将上一层的$n_1$个特征进行非线性映射,映射为$n_2$个特征,该层卷积核大小为$f_2*f_2$
重建
该卷积层将会把上一层的$n_2$个特征映射为高分辨率图像的Y通道。该层卷积核大小为$f_3*f_3$
图片数据的预处理
训练集和测试集的数据需要根据算法从图片中采集。
因为进行卷积操作,输出的数据矩阵会比输入矩阵的维度小,所以标签数据要比上采样图像小(f1//2 + f2//2 + f3//2)*2。
标签数据和上采样图像的来源
将下载好的图片作为标签数据。
上采样图像为原图通过双立方插值的方法,缩小$scale$倍再放大$scale$倍,得到的和原图大小相同的模糊图像。
处理方式
将每张图片按照特定步长分割成小方块,上采样图像和标签图像的小方块一一对应,最后将所有数据打乱顺序,存储在本地文件中。使用相同的方式将不同的两组图片集分别做成训练集和测试集。
算法分析
数据预处理
为了减少模型训练的时间,仅使用了一部分SRCNN官方论文提供的图片作为数据源。分别对其中的45张和77张进行了处理,生成两组训练数据集,分别为
train2.h5,train3.h5。 处理时,将每一张图片进行上采样,并将上采样结果拆分成许多$3333$大小的方块作为训练集上采样图像。同时将原图对应位置的$3333$方块中心的$21*21$大小的方块作为训练集的标签。两个对应的方块作为一对,最终将所有数据按照对为基本单位进行打乱,存储在hdf5文件中。其中33和21的大小设置参考的SRCNN论文,理论上大小是可以修改的,只要两者的差值等于
(f1//2 + f2//2 + f3//2)*2即可。 测试集数据的处理同上。使用的测试数据集为$Set5$。
训练模型
首先使用pytorch进行卷积神经网络的搭建。因为卷积操作会缩小图片,在测试模型时,为了保证输入输出的维度大小一致,为卷积核增加了padding。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class SRCNN(nn.Module):
def __init__(self, isTrain):
super(SRCNN, self).__init__()
c = 1
n1 = 32
n2 = 16
if isTrain:
self.conv1 = nn.Conv2d(c, n1, 9)
self.conv2 = nn.Conv2d(n1, n2, 1)
self.conv3 = nn.Conv2d(n2, c, 5)
else:
self.conv1 = nn.Conv2d(c, n1, 9, padding=9 // 2)
self.conv2 = nn.Conv2d(n1, n2, 1)
self.conv3 = nn.Conv2d(n2, c, 5, padding=5 // 2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x 训练时,将训练集数据的batch大小设为128,测试集为2。模型的损失函数采用MSE函数。使用学习率为0.0001的Adam进行模型参数优化。
因为训练模型花费时间过长,本次作业使用
train2.h5分别进行了进行20轮和50轮训练,使用train3.h5进行5轮和30轮训练。其中train3.h5使用n1=64,n2=32来训练模型。测试模型
将图片使用立方插值的方式缩小,作为小图,原图片作为大图。只要使用原图与测试模型得到的放大结果计算PSNR值,即可量化模型的判断标准,并且可以与立方插值方法进行对比。其中需要注意的是,测试模型时为了保证得到的图片和原图大小一样,需要为卷积核设置padding,这是训练模型时不需要的。同时,因为放大图片会导致图片边缘的像素计算不准确,在计算PSNR时,需要根据放大倍数对图像的边界进行裁剪。令人感到遗憾的是,我训练出来的这几个模型,PSNR值均未超过双立方插值的。
实验结果
训练出的四个模型分别放在项目目录下
1 | model:sr3 使用n1=64 n2=32, train3.h5训练集 训练5轮,测试模型得到的PSNR值 |
虽然模型的效果并不如二次立方插值,但是PSNR值在30以上,还算可以接受吧..
原图

放大3倍得到的图片

问题思考
因为看论文中模型得到的结果还是很不错的,PSNR值能达到32.26,但是我的模型效果就没有那么好,最好的模型只有30.97,还不如双三次插值的效果好。分析影响模型效果的因素有:$n_1,n_2$的选取,模型训练的轮数,数据集的大小。虽然该神经网络模型只有三层,但由于没有找到适合本机的支持gpu的pytorch版本,训练模型使用cpu进行计算,速度很慢。为了减少时长,我并没有使用论文中提供的全部91张图片作为训练数据,也并没有采用论文中说的$n_1=64,n_2=32$来训练,而是减半。训练的轮数也并没有很多。可能这就是我的模型效果不好的原因吧。因为随着训练轮数的增加,PSNR数值的增长会变慢,所以为了得到论文中那样的结果,可能需要使用91张照片的全数据集训练上百轮或千轮才能得到。
参考论文:Chao DongChen Change LoyKaiming HeXiaoou Tang :Learning a Deep Convolutional Network for Image Super-Resolution
